图计算
图计算是一种处理复杂关系数据的强大工具,广泛应用于社交网络分析、生物信息学、推荐系统等领域。随着大数据时代的到来,图数据的规模和复杂性不断增加,对图计算系统提出了更高的要求。以下是关于图计算的一些关键技术和研究方向:
大规模图数据处理:
随着社交网络和语义Web等应用的兴起,大规模图数据的处理成为研究热点。云计算环境下的图数据管理与处理机制,包括图数据的存储方式、索引结构、分割策略等,是当前研究的重点[1]。
分布式图计算:
分布式图计算系统在处理大规模图数据时表现出优越的性能。分布式图计算框架中不确定性因素和不同类型图计算作业的鲁棒性分析,以及基于成本、效率和质量的容错技术评估框架,是研究的重要内容[2]。
图计算加速架构:
针对图计算应用特有的不规则执行行为,硬件加速架构设计成为提升性能的关键。定制化的计算流水线、访存子系统、存储子系统和通信子系统,显著提升了图计算的性能和能效[3]。
图计算模型:
图计算系统的计算模型多种多样,包括节点中心计算模型、边中心计算模型、路径中心计算模型和子图计算模型等。节点中心模型因其高效性在实际应用中得到广泛应用[4]。
图划分技术:
图计算体系结构和系统软件:
图计算体系结构和系统软件关键技术的研究进展,包括高性能计算、并行计算等技术的应用,旨在优化图计算过程[6]。
并发图计算优化:
面向并发图计算任务的高性能执行环境设计,解决资源竞争、数据竞争等问题,提升并发图计算任务的执行性能[9]。
存内计算架构:
面向图计算的存内计算架构研究,通过忆阻器、混合内存立方体等新型存储器件,避免大量数据移动,提高图计算的执行效率[10]。
专用加速器研究:
面向图计算的专用加速器研究,通过定制化的硬件架构,提升特定应用中的性能,解决通用处理器难以高效执行图计算应用的问题[11]。
外存模式图计算系统的性能优化研究,包括子图构建方法、混合I/O访问和顶点更新策略等,提升系统整体性能[12]。
面向图计算的内存系统优化技术,通过提高访存效率,改善系统性能[13]。
大规模图计算系统关键技术研究,包括高能效的大规模图计算系统设计,提升磁盘带宽利用率和减少磁盘访问量[14]。
分布式图计算框架混合计算模式的研究,结合同步与异步计算模式的优点,克服各自不足,获得最优性能[15]。
异构多核图计算系统研究,通过多核处理器的多线程,设计高效的基于协程的图计算编程模型,提升系统性能[16]。
超大规模异构体系结构的图计算系统研究,通过从核无锁数据分发技术和流水化的功能映射技术,提升系统性能[17]。
图计算在电网CPS中的应用场景研究,通过图数据建模方法和电网CPS业务风险评估的图计算算法,提升电网CPS的建模和耦合计算能力[18]。
平衡图划分算法在分布式图计算中的应用,通过引入Metis结合平衡图划分算法,提高分布式图割边率计算的准确性[19]。
基于图查询系统的图计算引擎设计,通过单一系统支持查询和计算操作,提高数据遍历性能和减少数据传输成本[20]。
这些技术和研究方向共同推动了图计算领域的发展,为处理大规模复杂关系数据提供了强大的工具和方法。
大规模图数据处理在云计算环境下的最新存储方式和索引结构是什么?
在云计算环境下,大规模图数据处理的最新存储方式和索引结构主要包括以下几种技术和方法:
分布式存储模型:如HDFS(HadoopDistributedFileSystem)被广泛用于存储大规模图数据。这种模型通过将数据分布在多个节点上来提高存储效率和数据访问速度[37]。
MapReduce计算模型:这是一种编程模型,用于处理和生成大规模数据集。它通过map和reduce函数来并行化计算,自动处理机器故障,并优化网络和磁盘的使用[31]。
基于MKd-Tree的索引技术:这是一种高层次的分布式树形索引结构框架,适用于处理高维属性和海量数据。它包括OMKd-Tree和MMKd-Tree两种构建方法,具有良好的可扩展性和较高的检索效率[32]。
分片位图索引机制:这是一种辅助索引机制,适用于云环境中的海量数据管理。它通过分片位图来提高查询性能,同时利用云环境中的并行计算资源来提升单条查询的响应速度[33]。
基于NoSQL的分布式可达性索引与查询框架:这种框架在不破坏原图中节点可达性的前提下,将大规模图进行划分成若干个子图,并通过创建跨边集来保留原图中各子图间的可达性信息。这种方法可以并行生成可达性索引,提高查询效率[36]。
Spark环境下的高效图数据处理机制:这种机制通过对分布式计算的特性分析,采取适合大规模图的分割算法、数据抽取的优化以及缓存、计算层与持久层结合机制,显著提高了图数据处理的效率[39]。
基于Multi-GPU平台的大规模图数据处理系统:如GFlow系统,它提出了全新的适用于Multi-GPU下的图数据Grid切分策略和双层滑动窗口算法,通过动态地加载数据分块从SSD存储至GPU设备内存,并顺序化聚合并应用处理过程中各GPU所生成的Updates,提高了性能表现[34]。
分布式图计算框架中,哪些容错技术评估框架被证明最有效?
在分布式图计算框架中,容错技术是确保系统可靠性和高效性的重要组成部分。我们可以评估几种有效的容错技术。
检查点机制:检查点机制是分布式图处理系统中常用的容错技术之一。它通过周期性地保存系统状态来实现故障恢复。然而,传统的阻塞式写检查点方法会带来额外的运行时开销,因为它需要暂停计算过程来写入检查点[41]。相比之下,非阻塞式写检查点方法允许检查点的写入和计算过程同时进行,从而降低了额外开销[41]。此外,基于混合策略的故障恢复方式,即在乐观恢复的基础上写入一个检查点用以保存各个节点上的顶点和边,也显示出了减少恢复开销的潜力[41]。
多级容错处理机制:针对磁盘驻留的类Pregel系统,提出了一种多级容错处理机制,该机制将故障分为计算任务故障和计算节点故障两类,并设计了不同的备份和恢复策略。这种方法通过利用本地磁盘上保留的图数据和远程的消息数据完成恢复,显著减少了冗余数据的写开销和网络开销[43]。
基于副本的容错机制:Imitator是一种利用顶点副本进行容错的机制,它可以在引入很小执行开销的情况下提供容错支持,并且恢复速度快。Imitator通过复用原有机制来降低执行开销,并利用整个集群的硬件资源进行并行恢复[44]。
动态检查点和优先级检查点技术:这些技术旨在减少备份次数和每个检查点中的数据规模,从而降低备份开销。特别是对于异步计算系统,提出的轻量级的计算重起点构造方法和异步检查点技术可以进一步提高故障恢复效率[48]。
弹性同步并行模型:虽然不直接关联到容错技术,但弹性同步并行模型通过允许分布式任务随时暂停本地计算,从而消除运行速度不同的任务在全局同步位置的等待开销,间接提高了系统的容错性和效率[48]。
图计算加速架构中,哪些定制化的硬件加速技术目前最为先进?
在图计算加速架构中,定制化的硬件加速技术目前最为先进的主要包括基于FPGA的加速器、面向图神经网络(GNN)的专用加速结构、以及针对动态图处理的可编程硬件加速器。
基于FPGA的加速器:FPGA(现场可编程门阵列)因其高度的可配置性和灵活性,在图计算加速领域得到了广泛应用。例如,文献[54]提出了一种可定制的FPGA加速器,用于加速二值化图神经网络(BiGCNs),通过不同的循环展开和内存分区因子的参数化,以及数据传输与计算的重叠,显著提高了硬件性能。此外,文献[55]介绍了一种基于FPGA的软硬件协同图计算加速系统,通过动态选择合适的存储模型和采用点数据缓存、边数据预取等优化方法,提升了整体图计算加速系统的性能。
面向图神经网络的专用加速结构:随着图神经网络(GNN)在人工智能领域的广泛应用,对高效图计算加速的需求日益增长。文献[52]综述了面向GNN应用的专用加速结构,这些结构通过定制计算硬件单元和片上存储层次,优化计算和访存行为,取得了良好的加速效果。文献[53]也提到了针对GNN加速的研究,强调了智能训练和推理算法、高效系统和定制硬件在加速GNN中的重要性。
针对动态图处理的可编程硬件加速器:动态图处理是分析随时间变化的图数据的重要领域。文献[58]提出了一种可编程硬件加速器TDGraph,采用拓扑驱动的增量执行机制来加速动态图的处理,实现了更加规则化的状态传递和更好的数据访问局部性,相较于目前先进的软件方法和现有的硬件方法,性能有显著提升。
目前最为先进的定制化硬件加速技术主要包括基于FPGA的加速器、面向GNN的专用加速结构以及针对动态图处理的可编程硬件加速器。
在图划分技术方面,最新的优化策略有哪些?
在图划分技术方面,最新的优化策略主要集中在处理动态图数据的增量和重划分问题上。可以总结出以下几种优化策略:
基于顶点组重分配的动态增量图划分算法:这种算法专注于处理大规模动态增量图的划分问题,通过设计实时处理不同单元更新类型的动态处理器,并在每次处理完单元更新后执行局部优化器来提高图划分的质量。这种方法利用改进的标签传播算法进行顶点组搜索,并使用提出的顶点组移动增益公式来衡量最有益的顶点组,从而优化图划分[66]。
基于启发策略的动态平衡图划分算法:该算法通过引入扰动策略来解决图的平衡划分问题,确保在子图边界点划分最优的基础上跳出局部最优,扩大搜索空间。这种方法在真实世界图上的实验结果表明,与常见的算法相比,它在割边率和平衡系数上都有显著的优化[67]。
混合内存系统的图划分性能优化:针对分布式图划分算法难以分析和调试的问题,设计了基于混合内存的单机图划分算法框架。该方法提出了基于邻边结构的图划分结果动态缓存管理策略,以提高缓存区邻居节点的搜索效率,并针对NVM寿命有限的问题,设计了基于内存页读写特征的迁移算法,实现了NVM+DRAM高效协同[68]。
面向图计算的存内计算架构研究中,新型存储器件(如忆阻器、混合内存立方体)的应用效果如何?
在面向图计算的存内计算架构研究中,新型存储器件如忆阻器和混合内存立方体的应用效果表现出显著的优势和潜力。
忆阻器作为一种新型存储器件,具有非易失性、高速、低功耗和高集成密度的特点,这些特性使其在存内计算架构中具有独特的优势。忆阻器能够将存储和计算融合在相同的器件中,从而降低数据在计算和存储单元之间的传输开销,大幅提升计算能效[77]。例如,基于3D忆阻器阵列的神经网络内存计算架构(FMC)通过将功能单元的外围电路聚集到一起,形成一个功能单元池供多个忆阻器阵列共享,显著提高了功能单元的利用率并减少了数据传输,实验结果显示在多个神经网络训练任务的情况下,功能单元的利用率能提升高达58.51倍[79]。
此外,忆阻器在存内计算中的应用还涉及到敏捷设计关键技术的研究,包括数据映射、行为仿真、器件建模和物理设计等方面。例如,在数据映射方面,提出了一种卷积神经网络中权重-忆阻器之间的数据映射方法,利用卷积计算中的数据复用机制,提高了并行度和能量效率[77]。在行为仿真方面,提出了一种面向存内计算的忆阻器阵列高效仿真模型,通过卷积自编码器模型进行求解,大幅提高了仿真速度和精度[77]。
混合内存立方体(HMC)作为一种新型DRAM架构,通过3D封装和硅通孔(TSV)技术,显著提高了内存系统的带宽、延迟、功率和密度[73]。这种架构能够有效地解决多核处理器性能受限于内存系统带宽的问题,为高性能计算提供了新的解决方案。
忆阻器和混合内存立方体在面向图计算的存内计算架构中表现出显著的优势,包括提高计算能效、提升功能单元利用率、减少数据传输开销以及增强系统性能等方面。
脑图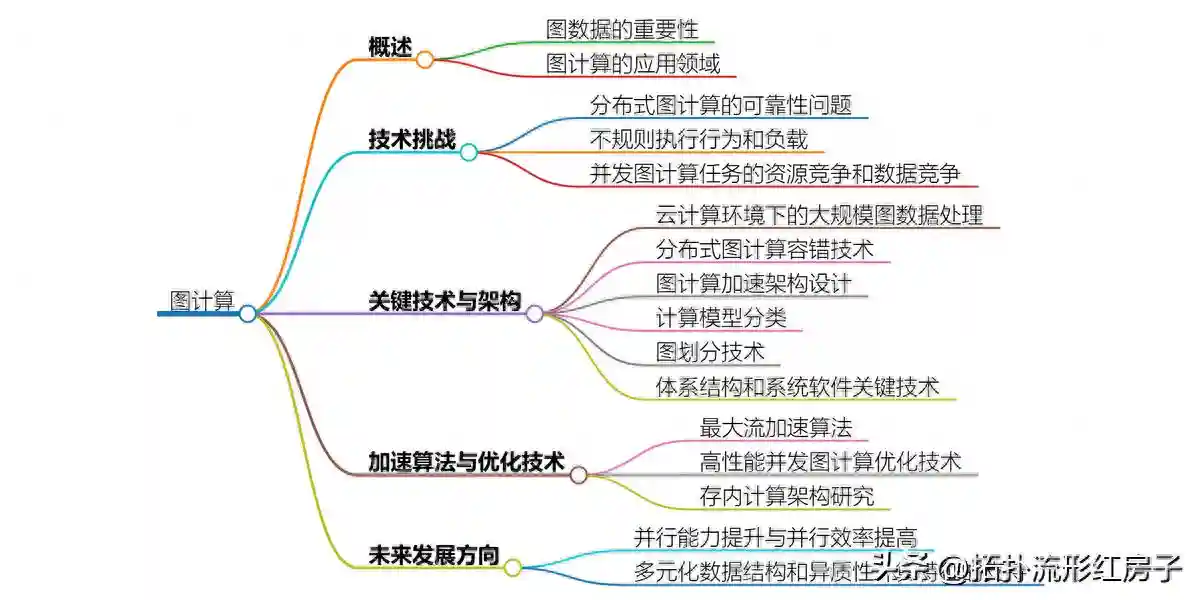
事件名称
事件时间
事件概述
类型
云计算环境下大规模图数据处理技术的研究与发展
2011-10-15
随着社交网络分析、语义Web分析等新兴应用的增长,对亿万个顶点级别的大规模图处理能力的需求日益迫切。
技术研究与发展
分布式图计算作业的容错技术研究
2021-07-05
面对图数据规模日益庞大和图计算作业复杂性的挑战,提出了一系列容错技术评估框架和容错机制。
技术研究与发展
图计算加速架构的提出与优化
2021-04-06
为了克服图计算应用面临的挑战,提出了大量的图计算硬件加速架构设计。
技术创新
图数据分析系统计算模型的研究现状综述
2017-02-07
调研和综述了图计算系统中的计算模型,介绍了主流图计算系统的分类和节点中心计算模型的应用。
技术研究与发展

面向分布式图计算的图划分技术研究
2024/03/07
未知
相关组织组织名称
概述
类型
StreamGraphChi
一个基于“边为中心”流处理的单机大规模图计算系统。
科技/软件
Mernmaid
与StreamGraphChi一同被提出,旨在提升基于磁盘的单机大规模图计算系统性能。
科技/软件
TuNao
高能效的可重构图计算加速器,旨在利用图计算专用硬件促进大规模图结构数据的高能效处理。
科技/软件
FAHT(FastApproximateHashTables)
快速近似哈希查找表,用于加速数据库查询性能。
科技/软件
神威·太湖之光
世界上Top500排名第一的超级计算机,用于超大规模图计算系统的研究。
科技/超级计算机
Google的Pregel
全局、批量处理的图处理系统,但不能实现对图的实时计算。
科技/搜索引擎
参考文献1.于戈,谷峪,鲍玉斌等.云计算环境下的大规模图数据处理技术[J].计算机学报,2011.
2.张程博,李影,贾统.面向分布式图计算作业的容错技术研究综述[J].软件学报,2021.
3.严明玉,李涵,邓磊等.图计算加速架构综述[J].计算机研究与发展,2021.
4.刘梦雅,刘燕兵,于静等.图数据分析系统计算模型综述[J].计算机应用研究,2017.
5.华东师范大学计算机科学与技术学院.面向分布式图计算的图划分技术综述[J].计算机研究与发展,2024.
6.张宇,姜新宇,余辉等.图计算体系结构和系统软件关键技术综述[J].计算机研究与发展,2023.
7.张如青,魏蔚,张永新.基于并行图计算框架大规模图最大流加速算法[J].计算机仿真,2021.
8.李金忠,彭蕾,刘欢等.大规模图计算系统研究进展[J].小型微型计算机系统,2017.
9.赵进.高性能并发图计算优化技术研究[D].华中科技大学,2022.
10.黄禹.面向图计算的存内计算架构研究[D].华中科技大学,2022.
11.姚鹏程.面向图计算的专用加速器研究[D].华中科技大学,2022.
12.徐湘灏.外存模式图计算系统的性能优化研究[D].华中科技大学,2021.
13.王靖,张路,王鹏宇等.面向图计算的内存系统优化技术综述[J].中国科学:信息科学,2019.
14.周金红.大规模图计算系统关键技术研究[D].中国科学技术大学,2017.
15.丁鑫,陈榕,陈海波.分布式图计算框架混合计算模式的研究[J].小型微型计算机系统,2015.
16.钟文勇.异构多核图计算系统研究[D].湖南大学,2018.
17.林恒.基于超大规模异构体系结构的图计算系统研究[D].清华大学,2017.
18.王迪,郭庆来,孙宏斌.图计算在电网CPS中的应用场景研究[J].电网技术,2019.
19.罗冬梅.面向分布式图计算的平衡图划分算法[J].信息与电脑(理论版),2019.
20.柯学翰,陈榕.基于图查询系统的图计算引擎[J].大数据,2019.
21.于海燕,蔡鸿明,何援军.图学计算基础[J].图学学报,2013.
22.苗旭鹏,周跃,邵蓥侠等.GSO:基于图神经网络的深度学习计算图子图替换优化框架[J].计算机科学,2022.
23.刘苧,李东升,张一鸣等.大规模图计算系统综述(英文)[J].FrontiersofInformationTechnologyElectronicEngineering,2020.
24.吴城文,张广艳,郑纬民.从系统角度审视大图计算[J].大数据,2015.
25.谭俊,张国芳,刘广一等.基于图计算的配电网建模与分析[J].供用电,2019.
26.申林,薛继龙,曲直等.IncGraph:支持实时计算的大规模增量图处理系统[J].计算机科学与探索,2013.
27.,HansJohnson.“ImageCalculator.”TheInsightJournal(2005).
28.G..“GraphicalCalculus.”Nature
29.
30.XiaoningBian,QuanlongWang.“GraphicalCalculusforQutritSystems.”(2015).
31.MuthuDayalan.“MapReduce:simplifieddataprocessingonlargeclusters.”(2008).
32.雷婷.云环境下基于MKd-Tree的大规模图数据索引技术[J].电讯技术,2013.
33.孟必平,王腾蛟,李红燕等.分片位图索引:一种适用于云数据管理的辅助索引机制[J].计算机学报,2012.
34.张珩,张立波,武延军.基于Multi-GPU平台的大规模图数据处理[J].计算机研究与发展,2018.
35.JananiBalaji,RajshekharSunderraman.“Scalablestoragestructureforpatternmatchingonbiggraphdata.”2015IEEEInternationalConferenceonBigData(BigData)(2015).
36.张刘畅.基于NoSQL的社交网络图数据可达性索引技术研究[D].沈阳航空航天大学,2017.
37.张仁波.云计算环境下图计算关键处理技术研究与实现[D].北京邮电大学,2014.
38.BinYu,ChenZhangetal.“MassiveGISSpatio-temporalDataStorageMethodinCloudEnvironment.”InternationalConferenceonComputerScienceandArtificialIntelligence(2018).
39.杨天晴,王津,杨旭涛等.一种Spark环境下的高效率大规模图数据处理机制[J].计算机应用研究,2016.
40.何婧.面向云计算的多维数据索引研究[D].电子科技大学,2016.
41.杨溢.面向分布式图处理系统的高效容错技术[D].华东师范大学,2021.
42.ChenXu,“OnFaultToleranceforDistributedIterativeDataflowProcessing.”IEEETransactionsonKnowledgeandDataEngineering(2017).
43.毕亚辉,姜苏洋,王志刚等.面向磁盘驻留的类Pregel系统的多级容错处理机制[J].计算机研究与发展,2016.
44.王彭.分布式图计算系统的容错机制研究[D].上海交通大学,2015.
45.“Distributedfault-tolerancetechniquesforlocalcomputations.”(2007).
46.ElMoustaphaOuld-Ahmed-Vall,“DistributedFault-ToleranceforEventDetectionUsingHeterogeneousWirelessSensorNetworks.”IEEETransactionsonMobileComputing(2012).
47.,“ADecentralizedFaultTolerantmodelforGridComputing.”(2014).
48.王志刚.分布式大图迭代计算技术研究[D].东北大学,2017.
49.“MathematicalProgramsforBeliefPropagationandConsensus.”ArXiv(2015).
50.,MosharafChowdhuryetal.“ResilientDistributedDatasets:AFault-TolerantAbstractionforIn-MemoryClusterComputing.”SymposiumonNetworkedSystemsDesignandImplementation(2012).
51.杨赟,余辉,赵进等.面向动态有向图的单调图算法硬件加速机制[J].中国科学:信息科学,2023.
52.李涵,严明玉,吕征阳等.图神经网络加速结构综述[J].计算机研究与发展,2021.
53.ShichangZhang,AtefehSohrabizadehetal.“ASurveyonGraphNeuralNetworkAcceleration:Algorithms,Systems,andCustomizedHardware.”ArXiv(2023).
54.ZiweiWang,ZhiqiangQueetal.“CustomizableFPGA-basedAcceleratorforBinarizedGraphNeuralNetworks.”2022IEEEInternationalSymposiumonCircuitsandSystems(ISCAS)(2022).
55.曾圳.基于FPGA的软硬件协同图计算加速系统[D].华中科技大学,2021.
56.徐冲冲.基于FPGA的图计算加速器系统的研究[D].中国科学技术大学,2018.
57.,“AutomaticGenerationofEfficientAcceleratorsforReconfigurableHardware.”2016ACM/IEEE43rdAnnualInternationalSymposiumonComputerArchitecture(ISCA)(2016).
58.杨赟.动态图处理硬件加速机制研究[D].华中科技大学,2023.
59.王凯,宁钰,周威.基于Qt/Embedded的图形硬加速方法研究与实现[J].计算机技术与发展,2018.
60.StefanoSordillo,AbdallahCheikhetal.“CustomizableVectorAccelerationinExtreme-EdgeComputing:ARISC-VSoftware/HardwareArchitectureStudyonVGG-16Implementation.”Electronics(2021).
61.JianboShi,“Normalizedcutsandimagesegmentation.”ProceedingsofIEEEComputerSocietyConferenceonComputerVisionandPatternRecognition(1997).
62.KaimingHe,“DeepResidualLearningforImageRecognition.”2016IEEEConferenceonComputerVisionandPatternRecognition(CVPR)(2015).
63.,“"GrabCut".”ACMTransactionsonGraphics(TOG)(2004).
64.ZhenyuWu,“AnOptimalGraphTheoreticApproachtoDataClustering:TheoryandItsApplicationtoImageSegmentation.”(1993).
65.,“ImageNetclassificationwithdeepconvolutionalneuralnetworks.”CommunicationsoftheACM(2012).
66.李贺,刘延娜,杨舒琪等.基于顶点组重分配的动态增量图划分算法[J].软件学报,2023.
67.李琪,钟将,李雪.基于启发策略的动态平衡图划分算法[J].计算机研究与发展,2017.
68.李琪,钟将,李雪.图划分在混合内存系统的实现与性能优化[J].计算机学报,2018.
69.李贺,刘延娜,袁航等.动态图划分算法研究综述[J].软件学报,2023.
70.JianbingShen,YunfanDuetal.“InteractiveSegmentationUsingConstrainedLaplacianOptimization.”IEEETransactionsonCircuitsandSystemsforVideoTechnology(2014).
71.“Memristor-Themissingcircuitelement.”IEEETransactionsonCircuitTheory(1971).
72.SongtaoLing,ChengZhangetal.“EmergingMXene‐BasedMemristorsforIn‐Memory,NeuromorphicComputing,andLogicOperation.”AdvancedFunctionalMaterials(2022).
73.,“HybridmemorycubenewDRAMarchitectureincreasesdensityandperformance.”2012SymposiumonVLSITechnology(VLSIT)(2012).
74.ShaharKvatinsky,DmitryBelousovetal.“MAGIC—Memristor-AidedLogic.”IEEETransactionsonCircuitsandSystemsII:ExpressBriefs(2014).
75.黄晓弟.面向非易失逻辑应用的氧化铝基忆阻器研究[D].华中科技大学,2022.
76.,SeungJuKimetal.“MemristiveDevicesforNewComputingParadigms.”AdvancedIntelligentSystems(2020).
77.张宇航.面向忆阻器存内计算的敏捷设计关键技术研究[D].上海交通大学,2022.
79.毛海宇,舒继武.基于3D忆阻器阵列的神经网络内存计算架构[J].计算机研究与发展,2019.
80.WeiWang,“FPGAbasedonintegrationofmemristorsandCMOSdevices.”Proceedingsof2010IEEEInternationalSymposiumonCircuitsandSystems(2010).